Что такое инфографика и визуализация данных
В кулуарах датавиз-сообщества последние пару недель обсуждается вопрос терминов. Что такое визуализация данных? Что такое инфографика? Как они соотносятся? Это смежные области? Или одно часть другого? Споры не останавливаются.
Лет 8-9 назад мне было очень интересно тоже в этом разобраться. Я потратил достаточно много времени на это, но всё уложил у себя в голове. Понятно и непротиворечиво. Через мои лекции я думаю прошли сотни, может быть тысячи человек, там я про это рассказывал. Но нигде не публиковал. А то, что не опубликовано в интернете (а лучше в книге) вообще не существует.
Исправляю этот пробел сейчас, хотя бы кратко.
Итак, проблема возникла со стороны дизайнеров крупных форм инфографики в конце 1980-х и в 10-х закрепилась со стороны маркетологов. Дизайнеры в газетах начали делать не только небольшие графики, типа таких:

Но и создавать всё более и более масштабные полотна, занимая целую полосу и иногда разворот. Естественно, там в рамках одной композиции объединялись разные графики, карты, блоки с текстом и так далее.

Со временем эти композиции начали превращаться в особый жанр. И авторы из разных изданий начали соревноваться, кто это сделает круче. (Хотя это не означает, что до этого такого формата не было. У меня есть книга c инфографикой от National Geographic’s за 130 лет, она вся из таких картинок и состоит). Кому-то пришло в голову подписывать это Information Graphics (информационная графика), что позднее сократилось просто до Infographics (инфографика).
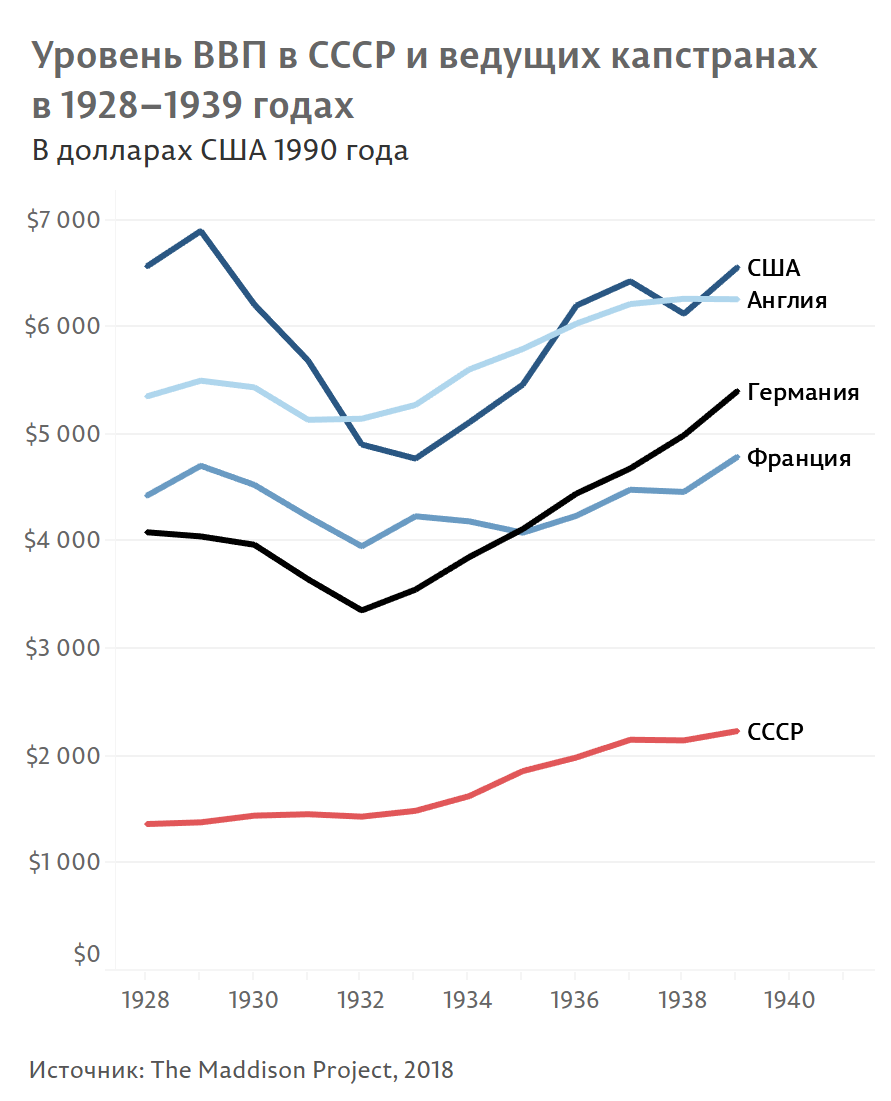
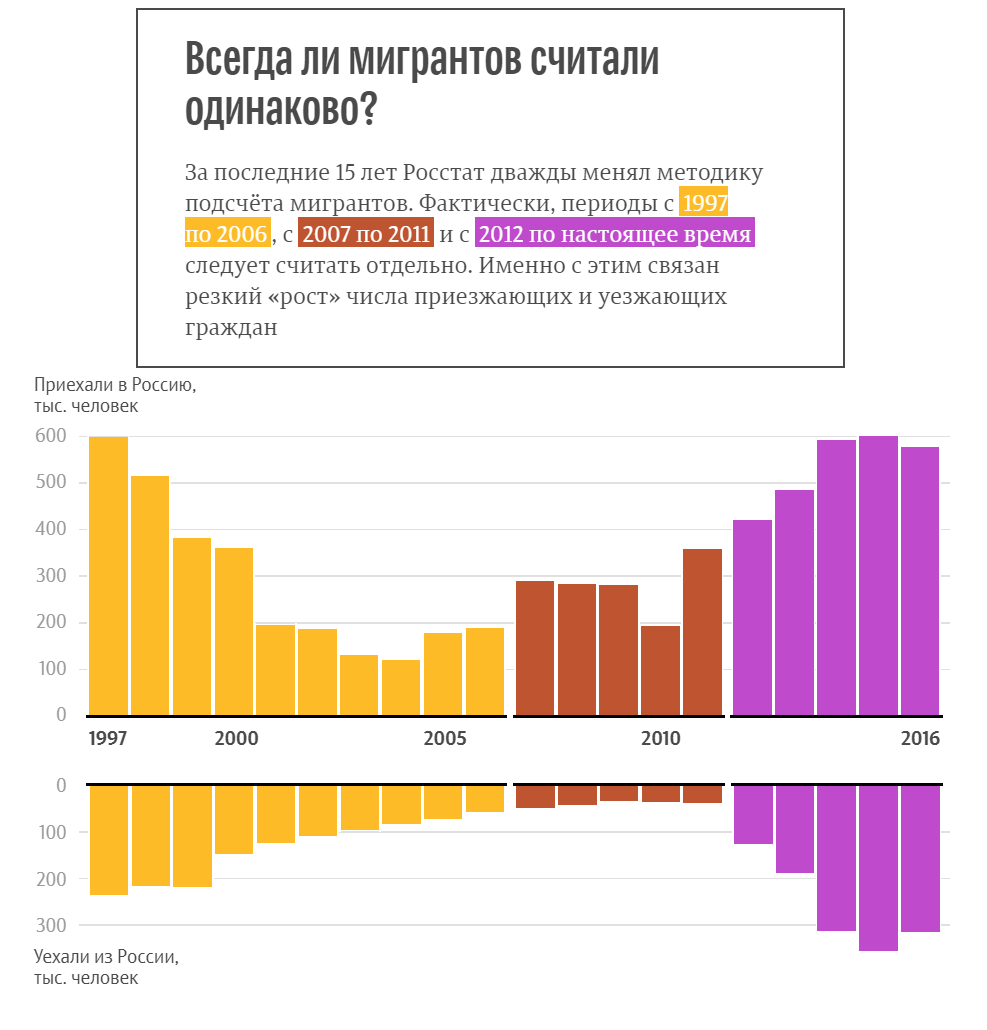
На графике мы видим, что information graphics раньше использовалось шире.

А вот с конца нулевых и десятых началось:

А началось то, что термин взяли на вооружение маркетологи. В их представлении инфографика — это было яркое, красивое, привлекающее внимание, с векторными иконочками человечков, крупными цифрами, в идеале что-то понятно объясняющее. Причем часто там могло никакой инфографики и вовсе не быть)

Картинки подобные этой засорили тогда весь интернет. И многие до сих пор считают, что это инфографика и есть. Более того, от Роберта Косары и других авторов подобное определение перекочевало в тысячи статей, и даже в энциклопедии. Но от этого оно не стало верным. Более того, это «определение» всё запутало. Есть целые статьи, их сотни, где описаны различия между инфографикой и визуализацией данных, что по моему мнению просто абсурд. Как отличия между транспортным средством и автомобилем.
===
Что же такое инфографика и визуализация данных? Давайте прочитаем википедию.
«Инфографика — визуализация данных или идей, целью которой является донесение сложной информации до аудитории быстрым и понятным образом. Средства инфографики помимо изображений могут включать в себя графики, диаграммы, блок-схемы, таблицы, карты, списки».
В целом это не худшее определение, по крайней мере оно явно дает понять, что графики, диаграммы и карты — это «средства инфографики», а не что-то смежное. Но откуда в определении взялась «цель» и «сложная» информация? А если информация не очень сложная, а если цель какая-то другая? И что там делают таблицы и списки?
В английской версии «Infographics (a clipped compound of „information“ and „graphics“) are graphic visual representations of information, data, or knowledge intended to present information quickly and clearly». В целом тоже неплохо, написано что это своеобразное сокращение от «информационная графика», и там уже указано про представление информации, данных или знаний. Но зачем-то опять созданное, чтобы представить информацию быстро и ясно.
На мой взгляд определение должно быть более общим.
Инфографика — графическое представление данных, информации, знаний в форме графиков, карт, схем и подобного. Сюда можно добавлять еще какие-то слова, но это определение исчерпывающе описывает то, что инфографика делает — показывает информацию или знания в графической форме. Добавляя про графики, карты и схемы мы с одной стороны отстраиваемся от маркированных списков и таблиц (которые в общем виде инфографикой не являются), с другой — от чисто пиктографики, не образующей какую-то композицию или схему.
Таким образом, УЖЕ ОЧЕВИДНО, что визуализация данных — это ОСНОВНОЙ элемент инфографики. Любое графическое представление данных в форме геометрических примитивов, чем и является визуализация данных — это уже по умолчанию инфографика. Но не всякая инфографика сводится разумеется к визуализации данных.

На схеме сборки шкафа от Икеи никаких данных нет, но это инфографика. На взрыв-схеме велосипеда — тоже, но это тоже инфографика. По ощущениям, особенно сейчас, после взлета популярности бизнес-аналитики, дэшбордов и подобного визуализации данных НАМНОГО БОЛЬШЕ, чем других видов инфографики (95%, а может и больше).
Разберем более редкие и сложные случаи.
Что есть в таком случае схемка для презентации, нарисованная на салфетке?

Это пограничная зона. Если в этом есть хоть какой-то смысл связи одних частей с другими, то это инфографика. Если это чисто декоративное изображение, то это скорее просто иллюстрация.
Является ли инфографикой атлас анатомии? Если там нарисован человек или одна кость, но больше ничего не подписано, то нет. Это просто иллюстрация. Если там появляются дополнительные слои информации, например выноски, объясняющие какая часть кости как называется, это уже такая прото-инфографика. Если там тело в разрезе, то безусловно инфографика.

Является ли любой чертеж инфографикой? Да, конечно. Это графическое представление объекта в схематичной форме.
Является ли дата-арт инфографикой? Очевидно, причем он еще и является при этом разновидностью визуализации данных.
===
Как же в таком случае разделить простейший график и огромные композиции на целый разворот? Разве эти композиции не заслужили отдельного слова?

На мой взгляд нет, но можно их называть комплексной инфографикой. И тогда туда может входить и то, что само по себе инфографикой не является — иллюстрации, крупные цифры, иконки, таблицы, маркированные списки и т. д.
Вот так всё просто, пользуйтесь.